Updates
- 07/30 : Updated extra credit due date.
- 07/30 : Released Extra Credit!
- 07/27 : Released Part 2.
- 07/23 : Removed all redundant size constraints from intro; all constraints given in description of each part.
- 07/23 : Indicated that
_mm_load_ssand_mm_loadu_psare allowed, while_mm_load_psis not. - 07/23 : Clarified testing for matrices other than 36x36.
- 07/21 : Updated benchmark.c
- 07/21 : Updated project to specify target machines as 330 Soda workstations.
- 07/21 : Part 1 posted.
- 07/21 : Part 0 added.
Background
Lately, one of your professors has been performing research in scientific computing. The latest project involves matrix multiplication, but unfortunately, nobody in the research group is familiar with any of the Great Ideas In Computer Architecture, let alone Flynn's Taxonomy! In order to optimize their code, they turn to you, a rising CS61C student. As always, the matrix multiplication (inner product) operation is defined as below:
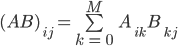
Normally, a programmer would seek out a fast linear algebra library for such an application. However, there are some interesting features of this problem that your more-specific code can account for. Here, the matrix multiply is of the form A * B. However half of your matrices are generated in legacy code written by those pesky FORTRAN programmers, so matrix A is stored in column-major format, while matrix B is stored in row-major format!
Furthermore, the size of the input matrix B is guaranteed to be such that MB = NA and NB = MA. This guarantees a square output matrix of size MA by MA! Therefore, your function will be passed MA and NA as parameters -- this fully defines the sizes of both input matrices (make sure you see why!).
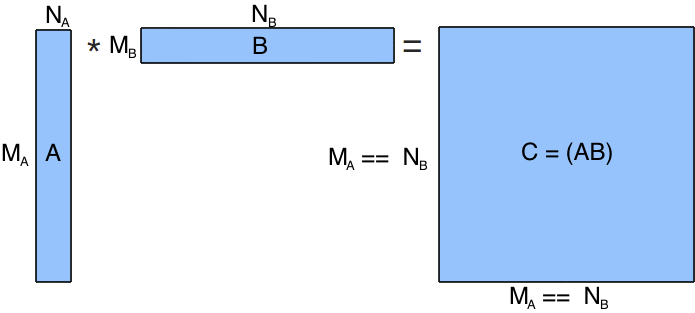
The output matrix C is to be stored in column-major format.
Using data-level (and later thread-level) parallelism, your goal is to replace a poorly designed naive algorithm with one reaching new heights of performance!
Architecture
What follows is information concerning the computers you will be working on. Some of it will be useful for specific parts of the project, but other elements are there to give you a real world example of the concepts you have been learning, so don't feel forced to use all of the information provided.
You will be developing on the hive Ubuntu workstations. They are packing not one, but two Intel Xeon E5620 microprocessors (codename Gainstown). Each has 4 cores, for a total of 8 processors, and each core runs at a clock rate of 2.40 GHz.
Each core comes with 16 general purpose integer registers (though a few are reserved such as the stack pointer). They also have 16 XMM registers a piece for use with the SIMD intrinsics.
All caches deal with block sizes of 64 bytes. Each core has an L1 instruction and L1 data cache, both of 32 Kibibytes. A core also has a unified L2 cache (same cache for instructions and data) of 256 Kibibytes. The 4 cores on a microprocessor share an L3 cache of 8 Mibibytes. The associativities for the L1 instruction, L1 data, unified L2, and shared L3 caches are 4-way, 8-way, 8-way, and 16-way set associative, respectively.
Getting Started
For this project, you will be required to work in groups of two. You are not allowed to show your code to other students. You are to write and debug your own code in groups of 2. Looking at solutions from previous semesters is also strictly prohibited.
To begin, copy the contents of ~cs61c/proj/su13_proj2 to a suitable location in your home directory. The following files are provided:
- Makefile: allows you to generate the required files using make
- benchmark.c: runs a basic performance and correctness test using a random matrix
- sgemm-naive.c: a sample program that calculates AB according to the rules defined by the problem in an inefficient manner
You can compile the sample code by running make bench-naive in the project directory. You do not need to modify or submit any of the provided files. Instead, you will be submitting two new files called sgemm-small.c (for part 1) and sgemm-openmp.c (for part 2).
You are not permitted to use the following optimizations for either part of the project:
- Aligned Loads / Stores (you are allowed to use mm_loadu_ps, but not mm_load_ps)
Please post all questions about this assignment to Piazza, or ask about them during office hours. Extra office hours will be held for the project, times for Part 2 are to be determined.
Office hours for Part 1 will be held at the following times in 330 Soda:
- Monday, July 22nd @ 7:00pm-8:30pm
- Monday, July 22nd @ 12:00pm-1:00pm
- Tuesday, July 23rd @ 7:00pm-8:30pm
- Wednesday, July 24th @ 8:00am-9:00am
- Wednesday, July 24th @ 12:00pm-1:00pm
- Friday, July 26th @ 5:00pm-7:00pm
- Saturday, July 27th @ 2:00pm-4:00pm
- More to be announced soon!
Part 0: Due Wednesday, July 24, 2013 at 23:59:59PDT (0pts)
This project differs from the others in the course in that it is a partner project. In the past, their have been issues with last-minute shuffles in teams that result in some students being left in very desperate situations. In an effort to avoid this, the staff will be requiring the submission of a file, proj2-0.txt, that has the following contents:
login1, name1 login2, name2
Here is an example of a complete proj2-0.txt file:
cs61c-tb, Albert Magyar cs61c-zz, John Doe
This part will be due on Wednesday, July 24th to establish a cut-off date after which your partner choices are final. This will help prevent any last-minute surprises. Type submit proj2-0 from a directory containing your proj2-0.txt file to submit this portion -- only one submission is required per two-person team!
Part 1: Due Sunday, July 28, 2013 at 23:59:59PDT (55pt)
Optimize a single precision AB matrix multiply for the special case where both A and B are size 36x36. You are to compute the matrix C = AB. Place your solution in a file called sgemm-small.c. You can create a template file by typing cp sgemm-naive.c sgemm-small.c. You will also need to add an appropriate #include directive before you can use SSE intrinsics. To compile your improved program, type make bench-small. You can develop on any machine that you choose, but your solution will be compiled using the given Makefile and will be graded on the 330 Soda machines. When you are done, type submit proj2-1.
Tune your solution for matrices of size 36x36. To receive full credit, your program needs to achieve a performance level of 10.5Gflop/s for matrices of this size. This requirement is worth 35pt. See the table below for details.
Your code must be able to handle small matrices of size other than 36x36 in a reasonably efficient manner. Your code will be tested on matrices with m_a=[32,100] and n_a=[32,300], and you will lose points if it fails to achieve an average of 5Gflop/s on such inputs. An effective way to avoid dealing with fringe cases is by padding the matrices with zeros so that they are of a more optimal size. This requirement is worth 20pt.
NOTE: the starting configuration of the Makefile only tests 36x36 matrices. Change the upper bound in the loops over m and n values to try different sizes. You are responsible for ensuring your code works on all sizes of matrices in the range described above!
For this part, you are not allowed to use any other optimizations. In particular, you are not permitted to use OpenMP directives. Cache blocking will not help you at this stage, because 36x36 matrices fit entirely in the cache anyway (along with all other sizes we are testing in Part 1). Remember that aligned loads are prohibited for both parts.
We recommend that you implement your optimizations in the following order:
- Use SSE Instructions (see lab 7)
- Optimize loop ordering (see lab 6)
- Implement Register Blocking (load data into a register once and then use it several times)
- Implement Loop Unrolling (see lab 7)
- Compiler Tricks (minor modifications to your source code can cause the compiler to produce a faster program)
36x36 Matrix Grading
| Gflop/s | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 10.5 |
| Point Value | 1 | 4 | 7 | 10 | 15 | 20 | 25 | 30 | 32 | 34 | 35 |
Intermediate Glop/s point values are linearly interpolated based on the point values of the two determined neighbors and then rounded to nearest integer. Rounding modes are to be determined. Note that heavy emphasis is placed on the middle Gflop/s, with the last couple being worth very few points. So don't sweat it if you are having trouble squeezing those last few floating point operations out of the machine!
Part 2: Due Sunday, August 4, 2013 at 23:59:59PDT (55pt)
The Objective
This part of the project will deal with inputs of large m_a but relatively small n_a. In order to deal with the larger problem sizes, you will have to employ cache blocking to preserve spatial locality of reference. Furthermore, you will use the compiler directives defined by the OpenMP framework to parallelize your computation across the 8 physical (16 logical with HyperThreading) cores of your workstation.
New Files
To begin, copy the contents of the ~cs61c/proj/su13_proj2-2 directory to your proj2 working directory. This will give you two new files and overwrite your Makefile with an updated version; together, these features will speed testing of arbitrarily-sized matrices.
We have added a modified benchmarking and testing file, tester.c to test specific matrix sizes, which you can compile with make bench-test. The Makefile has also been changed to allow for this. To test a specific pair of size parameters m_a == n_b and n_a == m_b, run the command below:
./bench-test m_a n_a
Note that the rule for bench-test uses the sgemm-openmp.c file for the definition of sgemm -- therefore, the code you wish to test must be in sgemm-openmp.c. The script testing.sh automatically compiles and runs tester.c on a set of matrices specified inside the script. The new files are tester.c and testing.sh, and Makefile has been modified. Be sure to obtain all of these files.
Submission and Grading
Place your solution in a file called sgemm-openmp.c. Test it using make bench-openmp and make bench-test (described above). Submit using submit proj2-2.
For Part 2, we will grade your average performance over a range of tall-and-skinny matrices A and short-and-wide matrices B. In more specific terms, the matrices will fit the criteria listed below, which fully specify all possible inputs. Specifications in black are identical to Part 1, while specifications in red are specific to Part 2.
- Compute
C = AB, storing the result in column-major format - Matrix
Ahasm_arows andn_acolumns, and is stored in column-major format. - Matrix
Bhasm_brows andn_bcolumns, and is stored in row-major format. m_a == n_bm_b == n_a1000 <= m_a <= 1000032 <= n_a <= 100
Any valid solution that achieves an average performance of 50Gflop/s over the specified size range without using prohibited optimizations (aligned loads and stores) will receive full credit (55pt).
A Note on Evaluating Average Performance
Note that, as always, there is no guarantee that we will exhaustively test every possible size within this set. Just as in any project, there are a finite number of test cases that are exercised in grading; for better or for worse, your score must reflect the average performance obtained with the set of sizes chosen for grading. Therefore, the only way to guarantee that you make the average performance specification is to ensure that no matrix size results in a performance noticably slower than the required average; relying on specific sizes that result in faster performance to ‚boost your average‚ will not work. We will try strange matrix sizes, such of powers-of-2 and primes...so be prepared. The set of sizes listed in testing.sh is not the final list to be used for grading!
Testing
We will be disabling remote logins on a few of the Hive workstations early in this coming week to allow for reliable testing of your matrix multiply code.
Matrix Range Grading
| Average Gflop/s | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 45 | 50 |
| Point Value | 0 | 5 | 10 | 15 | 25 | 35 | 45 | 50 | 55 |
Office hours for Part 2 will be held at the following times in 330 Soda:
- Sunday, July 28th @ 7:45pm-8:45pm
- Monday, July 29th @ 12:00pm-1:00pm
- Monday, July 29th @ 7:00pm-8:00pm
- Wednesday, July 31th @ 12:00pm-1:00pm
- Wednesday, July 31th @ 6:00pm-7:30pm
- Thursday, August 1st @ 7:00pm-8:00pm
- Friday, August 2nd @ 6:00pm-7:00pm
- Saturday, August 3rd @ 5:00pm-7:00pm
Extra Credit: Due Sunday, August 4, 2013 at 23:59:59PDT (10pt)
You will find the specification here.
Optimization Details
What follows are some useful details for Part 1 and Part 2 of this project.
Understanding Column- and Row-Major Flattenings
SSE Instructions
Your code will need to use SSE instructions to get good performance on the processors you are using. Your code should definitely use the _mm_add_ps, _mm_mul_ps, _mm_loadu_ps intrinsics as well as some subset of:
_mm_load1_ps, _mm_load_ss, _mm_storeu_ps, _mm_store_ss _mm_shuffle_ps, _mm_hadd_ps
Depending on how you choose to arrange data in registers and structure your computation, you may not need to use all of these intrinsics (such as _mm_hadd_ps or _mm_shuffle_ps). There are multiple ways to implement matrix multiply using SSE instructions that perform acceptably well. You probably don't want to use some of the newer SSE instructions, such as those that calculate dot products (though you are welcome to try!). You will need to figure out how to handle matrices for which N isn't divisible by 4 (the SSE register width in 32-bit floats), either by using fringes cases (which will probably need optimizing) or by padding the matrices.
To use the SSE instruction sets supported by the architecture we are on ( MMX, SSE, SSE2, SSE3, SSE4.1, SSE4.2 ) you need to include the header <nmmintrin.h> in your program.
Register Blocking
Your code should re-use values once they have been loaded into registers (both MMX and regular) as much as possible. By reusing values loaded from the A or B matrices in multiple calculations, you can reduce the total number of times each value is loaded from memory in the course of computing all the entries in C. To ensure that a value gets loaded into a register and reused instead of being loaded from memory repeatedly, you should assign it to a local variable and refer to it using that variable.
Loop Unrolling
Unroll the inner loop of your code to improve your utilization of the pipelined SSE multiplier and adder units, and also reduce the overhead of address calculation and loop condition checking. You can reduce the amount of address calculation necessary in the inner loop of your code by accessing memory using constant offsets, whenever possible.
Padding Matrices
As mentioned previously it is generally a good idea to pad your matrices to avoid having to deal with the fringe cases. This implies copying the entire matrix into a re-formatted buffer with no fringes (e.g. copy 3x4 matrice into 4x4 buffer). You should allocate this buffer on the heap. Be sure to fill the padded elements with zeros.
Cache Blocking
The first step is to implement cache blocking, i.e. loading chunks of the matrices and doing all the necessary work on them before moving on to the next chunks. The cache sizes listed in the Architecture section should come in handy here.
OpenMP
Once you have code that performs well for large matrices, it will be time to wield the formidable power offered to you by the machine's 8 cores. Use at least one OpenMP pragma statement to parallelize your computations.
Miscellaneous Tips
You may also wish to try copying small blocks of your matrix into contiguous chunks of memory or taking the transpose of the matrix in a precompute step in order to improve spatial locality.
References
- Goto, K., and van de Geijn, R. A. 2008.Anatomy of High-Performance Matrix Multiplication,ACM Transactions on Mathematical Software 34, 3, Article 12.
- Chellappa, S., Franchetti, F., and Püschel, M. 2008.How To Write Fast Numerical Code: A Small Introduction,Lecture Notes in Computer Science 5235, 196–259.
- Bilmes, et al.The PHiPAC (Portable High Performance ANSI C) Page for BLAS3 Compatible Fast Matrix Matrix Multiply.
- Lam, M. S., Rothberg, E. E, and Wolf, M. E. 1991.The Cache Performance and Optimization of Blocked Algorithms,ASPLOS'91, 63–74.
- Intel Instrinsics Guide (see Lab 7)
- Intel® 64 and IA-32 Architectures Optimization Reference Manual
- OpenMP reference sheet
- OpenMP Reference Page from LLNL