 |
 |
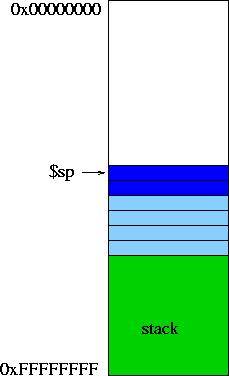 |
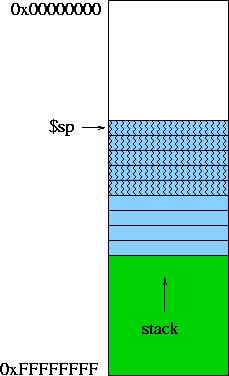
Figure 1 -- Typical Stack
The purpose of this project is to familiarize you with the details of the MIPS calling convention and enhance your assembly programming skills.
To submit your project, create a directory named proj2 that
contains your sprintf.s file. From within that directory, type "submit
proj2".
The deadline to submit your project is 11:59pm on July 20th.
This is an individual project, not to be done in partnership. Submit in your own work. Remember, you are allowed to discuss approaches, but NOT solutions.
This document mentions certain test cases. However, this input/output behavior is not a comprehensive specification of all possible behavior. Therefore, even if your project submission passes all of the test cases mentioned here, it may not be entirely correct. We strongly urge you to create test cases in addition to the ones provided here.
By now, you should know how to manage the stack when writing functions in MIPS. Let's assume you have a function light_blue, which calls a function dark_blue. The very first thing that light_blue does is to allocate space in the stack for its variables (prolog). In Figure 1 (middle) we can see that it allocates space for 4 words. light_blue eventually calls dark_blue, which allocates space for its own variables. Figure 1 (right) shows that dark_blue has allocated space for 2 words.
| |||||
| Figure 1 -- Typical Stack |
|||||
The MIPS function calling convention uses registers $a0-$a3
for passing arguments down to functions. If there are more than four,
the remaining arguments are passed on the stack. How is this mixed with
the normal stack managing? Each argument gets one word of stack space
(Why one word?). Suppose we are trying to write in MIPS assembler a
program like this:
int dark_blue (int lvl, int hp, int mp, int str, int agl, int spd, int intel, int vit, int ftg) {
int a;
...
a = spd;
...
}
int light_blue () {
int c, d, e;
...
dark_blue (c, d, e, 62, 25, 99, 47, 29, 1);
...
}
Procedure dark_blue has nine integer arguments. The first four arguments are placed on $a0-$a3 as expected. The remaining arguments are "spilled" onto the stack as part of the caller's (light_blue) stack frame. In other words, light_blue, not dark_blue, must allocate the space needed for the remaining arguments.
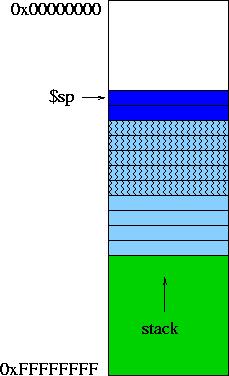
Figure 2 shows this stack management method. light_blue now allocates space in the stack for its variables and the arguments that it will use to call dark_blue. We can see in Figure 2 (middle) that it allocates space for 9 words: 4 for its own consumption, and 5 more for the spilled arguments in calling dark_blue
light_blue eventually calls dark_blue that then allocates space for its own variables. Figure 2 (right) shows that dark_blue has allocated space for 2 words. Note that dark_blue can access to the 5 arguments by accessing to the beginning of the stack reserved by its caller process (light_blue).
| |||||
| Figure 2 - Stack with Spilled Arguments |
|||||
The 5 spilled arguments (patterned light-blue stack) are located at the lower addresses of light_blue's stack frame.
That is, light_blue will use 0($sp) to store the argument agl, 4($sp) to store the argument spdy, and so on. Therefore, dark_blue will use 8($sp) to access to the argument agl, 12($sp) to access to the argument spd, and so on.
Note that the first spilled argument is always at the caller's stack frame lowest address, and the last spilled argument at the highest address. You have to be consistent about this so that dark_blue knows which argument is which.
light_blue:
# prolog
addi $sp, $sp, -16 # allocate stack space for 4 words:
# $ra, c, d, and e
sw $ra, 12($sp) # save $ra
# use 0($sp) to save c ($t0) when needed
# use 4($sp) to save d ($t1) when needed
# use 8($sp) to save e ($t2) when needed
# body
...
addi $t0, $0, 3 # assume this holds the value of c
addi $t1, $0, 4 # assume this holds the value of d
addi $t2, $0, 5 # assume this holds the value of e
...
# this is the call to dark_blue
addi $sp, $sp, -20 # allocate stack space for 5 "spilled" words (patterned
# light-blue): the args agl, spd, intel, vit, fatigue
sw $t0, 20($sp) # save c before calling dark_blue
sw $t1, 24($sp) # save d before calling dark_blue
sw $t2, 28($sp) # save e before calling dark_blue
add $a0, $0, $t0 # arg lvl = c
add $a1, $0, $t1 # arg hp = d
addi $a2, $0, $t2 # arg mp = e
addi $a3, $0, 62 # arg str = 62
addi $t0, $0, 25 # arg agl = 25, but no more registers
sw $t0, 0($sp) # so pass on the stack
addi $t0, $0, 99 # arg spd = 99, but no more registers
sw $t0, 4($sp) # so pass on the stack
addi $t0, $0, 47 # arg intel = 47, but no more registers
sw $t0, 8($sp) # so pass on the stack
addi $t0, $0, 29 # arg vit = 29, but no more registers
sw $t0, 12($sp) # so pass on the stack
addi $t0, $0, 1 # arg ftg = 1, but no more registers
sw $t0, 16($sp) # so pass on the stack
jal dark_blue
addi $sp, $sp, 20 # restore stack space used for calling dark_blue
...
# epilog
lw $ra, 12($sp) # reload return address
addi $sp, $sp, 16 # restore stack space
jr $ra # return to caller
...
dark_blue:
# prolog
addi $sp, $sp, -8 # allocate stack space for 2 words:
# $ra, a
sw $ra, 4($sp) # save $ra
# use 0($sp) to save a when needed
# body
...
add $t0, $0, $a1 # get argument hp
lw $t1, 20($sp) # *** (see below)
# 8 (dark_blue's frame) + 12 = 20 up on stack
# fetched argument vit
...
# epilog
lw $ra, 4($sp) # reload return address
addi $sp, $sp, 8 # restore stack space
jr $ra # return to caller
The instruction indicated by "***" is the key to understanding the stack method of argument passing. Function dark_blue
is referring to a word of stack memory that is from the caller's stack
frame. Its own frame includes only the two words 0($sp) and 4($sp).
Copy the contents of ~cs61c/public_html/su07/hw/proj2 to a suitable location in your home directory.
% cd ~ % cp -r ~cs61c/public_html/su07/assignments/proj2 ~/proj2You should have
sprintf.s, test.sprintf.s, and Makefile in ~/proj2. Your implementations must go in sprintf.s.
Test files are given to help you out, but they are by no means
comprehensive tests. We strongly urge you to create test cases in
addition to the ones provided here.
The first part of your project will be partially implementing the C sprintf function (see 'man sprintf') in MIPS. This is the function prototype for sprintf:
int sprintf (char *outbuf, char *format, ...)
sprintf works like printf, except that it writes to the string outbuf instead of to standard output. outbuf is assumed already to point to allocated memory sufficient to hold the generated characters. Your function must accept any number of arguments passed according to the MIPS standard convention.
The first argument is the address of a character array into
which your procedure will put its results. The second argument is a
format string in which each occurrence of a percent sign (%) indicates
where one of the subsequent arguments is to be substituted and how it
is to be formatted. The remaining arguments are values that are to be
converted to printable character form according to the format
instructions. sprintf returns the number of characters in its output string not including the null at the end.
You do not have to do any error checking (e.g. comparing the number of arguments to the number of % specifications). You also do not have to implement all of the formatting options of the real sprintf. Here are the ones you are to implement:
Don't implement width or precision modifiers (e.g., %6d ).
Formatting floating-point numbers is a hard problem. Therefore, we will use a different format than what the real sprintf produces.
Remember that the IEEE 754 standard defines 5 different encodings for single-precision FP numbers: zero, normalized numbers, denormalized numbers, NaN, and infinity. We want your sprintf implementation to support all of them. The good thing is that, for 4 out of the 5 encodings, you'll just copy to the output buffer the sign and a string stating what encoding uses the number (0, denorm, Inf, or NaN). You must only develop the real value for normalized numbers, and in that case, you will format the mantissa in binary, and the exponent in decimal.
| Single Precision | Object Represented | What you must write into the buffer | |
| Exponent | Mantissa | ||
| 0 | 0 | zero | [-]0 |
| 0 | nonzero | � denormalized number | [-]denorm |
| 1-254 | anything | � normalized number* | [-]mantissa_in_binary_2 x 2^([-]exponent_in_decimal) |
| 255 | 0 | � infinity | [-]inf |
| 255 | nonzero | NaN (Not a Number) | [-]NaN |
| * Note that there is a "_2 x " after the mantissa when it is printed out | |||
Consider the following piece of code:
.data __buffer: .space 200 __format: .asciiz "%f" __float: # here goes the code in the table's left column *** .text addi $sp, $sp, -20 # space for the stack of parameters la $t0, __buffer sw $t0, 0($sp) # 0($sp): __buffer la $t0, __format sw $t0, 4($sp) # 4($sp): __format la $t0, __float lw $t0, 0($t0) sw $t0, 8($sp) # 8($sp): __float (%f) jal sprintf
The following table shows some examples of how your sprintf code must deal with different floating point values. The left column of the table shows what goes in the line indicated by "***", and the right column what sprintf must write into the output buffer.
| Code in "***" | Output Buffer |
| .word 0xffff0000 | -NaN |
| .word 0x7f800000 | inf |
| .word 0x00100000 | denorm |
| .word 0x80000000 | -0 |
| .float 1.2e25 | 1.00111101101000110010101_2 x 2^(83) |
| .float 1048576.5 | 1.000000000000000000001_2 x 2^(20) |
| .float 1048576.125 | 1.00000000000000000000001_2 x 2^(20) |
| .float 1048576.0625 | 1.0_2 x 2^(20) |
| .float 0.5078125 | 1.000001_2 x 2^(-1) |
| .float -0.03125 | -1.0_2 x 2^(-5) |
| .float +1.125 | 1.001_2 x 2^(0) |
| .float -1.25 | -1.01_2 x 2^(0) |
| .float -1.5 | -1.1_2 x 2^(0) |
| .float -1.0 | -1.0_2 x 2^(0) |
To test your sprintf, you need to load two files in the correct order: run xspim (or spim), load test.sprintf.s, then load sprintf.s. Finally, run your program. The following Makefile may make your life easier. make sprintf will test your sprintf implementation Note: certain errors will not be reported by spim/xspim to you if you use the Makefile
From within the directory containing your code, run submit proj2. You must include the following files: sprintf.s, and README. Additionally, make sure no labels in your solutions begin with '__'. The testing framework will use labels that begin with __.
sprintf function must work with the main function supplied in test.sprintf.s .
$sp points to the lowest occupied space of the stack. This means you will need to move the stack pointer (i.e. addi $sp, $sp, 4) befor using the 0th offset of the stack pointer (i.e. sw $ra, 0($sp)).
sprintf.s.
$a0-$a3, they get their own registers; and if they are passed via the stack, they get their own word (i.e. use lw to read a character argument from the stack, do NOT use lb/lbu).
|
Q: For my sprintf implementation, can I use any label I want? A: Yes, with 2 exceptions: a) Don't use any label used in the test.sprintf.s file, and b) don't use any label that starts with two underscores ('_' character). For example, the label __mylabel is strictly forbidden. Q: Should I write the ASCII codes of the interesting characters? A: MIPS compilers are smart enough to understand C syntax to represent characters. For example, if you want to load into $t0 the value of the ASCII code for the % character, you can use: addi $t0, $0, '%'Note that this is way more readable than: addi $t0, $0, 37And readers like readable code (remember, a happy reader is a good reader). Q: To convert integers to its ASCII representation, do we need to create something like lab4's table? A: This is a way to do it. But, before you do it, you may want to take a look at the __putint function in the test.sprintf.s file we provide. It may give you a better idea. Q: How do we know how many arguments there are? A: The interesting thing about sprintf is not only that it may use more than 4 arguments, but also that the number of arguments is variable. The output buffer and the format string for sure (at least 2). Then, we have to check the format string:
Q: Are we allowed to used MIPS pseudoinstructions in this project (things like li and clear)? A: Yes. Q: What do you mean by proper register convention? A: "Proper convention" means, in register usage, that
Q: Can I have a .data section with my .s files A: Yes you can. Make sure all labels in the .data section do not start with '__' Q: Can I submit other .s files? A: No. Q: Can I use $fp? A: Yes. Q: How can I get UCB xspim for Windows? A: Assuming you have Cygwin, a UNIX emulation layer for Windows installed with X11 packages, download this unofficial binary/source. Extract the contents of the tarball into Keep in mind the project will be tested and graded by running them on the instructional machines (Solaris/sparc or Solaris/x86). You must verify your project works on one of these platforms (i.e. like nova). It is not good enough that it worked Cygwin/Windows. |