Updates
- 11/7: Project 4 release.
Clarifications/Reminders
- Start Early! Inevitably, hive machines will fill up later in the project, and the benchmarks will become unreliable when performed on crowded machines. Your autograded benchmarks will be based on the performance of your optimised code on an empty hive machine, so expect your benchmarks to be slightly lower than the benchmark that will be graded.
- This project should be done on the hive machines. The code will not compile on non-x86 machines and will likely perform differently on other machines configured differently to the hive machines.
- You may work with at most one (1) partner for this project. You may share code with your partner, but ONLY your partner. The submit command will ask you for your partner's name, so only one partner needs to submit.
- Remember to take a look at labs 8-10 for ideas on obtaining higher speedup ratios.
- AVX is not allowed.
Goals
In this project, you will learn to optimize your code with various methods including SIMD, OpenMP, and loop unrolling.
Background
Cameras traditionally capture a two dimensional projection of a scene. However depth information is important for many real-world application. For example, robotic navigation, face recognition, gesture or pose recognition, 3D scanning and more. The human visual system can preceive depth by comparing the images captured by our two eyes. This is called stereo vision. In this project we will experiment with a simple computer vision/image processing technique, called "shape from stereo" that, much like humans do, computes the depth information from stereo images (images taken from two locations that are displaced by a certain amount).
Depth Perception
Humans can tell how far away an object is by comparing the position of the object in the left eye's image with respect to right eye's image. If an object is really close to you, your left eye will see the object further to the right, whereas your right eye will see the object to the left. A similar effect will occur with cameras that are offset with respect to each other as seen below.
The above illustration shows 3 objects at different depth and position. It also shows the position in which the objects are projected into the image in camera 1 and camera 2. As you can see, the closest object (green) is displaced the most (6 pixels) from image 1 to image 2. The furthest object (red) is displaced the least (3 pixels). We can therefore assign a displacement value for each pixel in image 1. The array of displacements is called displacement map. The figure shows the displacement map corresponding to image 1.
Generating a depth map
In order to achieve depth perception, we will be creating a depth map. The depth map will be a new image (same size as left and right) where each "pixel" is a value from 0 to 255 inclusive, representing how far away the object at that pixel is. In this case, 0 means infinity, while 255 means as close as can be. Consider the following illustration:

The first step is to take a small patch (here 5x5) around the green pixel. This patch is represented by the red rectangle. We call this patch a feature. To find the displacement, we would like to find the corresponding feature position in the other image. We can do that by comparing similarly sized features in the other image and choosing the one that is the most similar. Of course, comparing against all possible patches would be very time consuming. We are going to assume that there's a limit to how much a feature can be displaced -- this defines a search space which is represented by the large green rectangle (here 11x11). Notice that, even though our images are named left and right, our search space extends in both the left/right and the up/down directions. Since we search over a region, if the "left image" is actually the right and the "right image" is actually the left, proper distance maps should still be generated.
The feature (a corner of a white box) was found at the position indicated by the blue square in the right image.
We'll say that two features are similar if they have a small Squared Euclidean Distance. If we're comparing two features, A and B, that have a width of W and height of H, their Squared Euclidean Distance is given by:
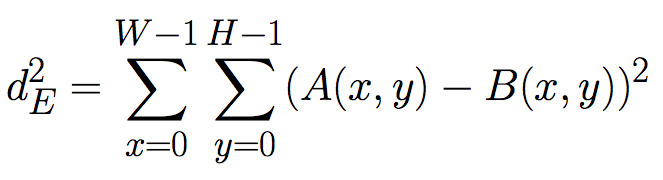
(Note that this is always a positive number.)
For example, given two sets of two 2×2 images below:
 ← Squared Euclidean distance is (1-1)2+(5-5)2+(4-4)2+(6-6)2 = 0 →
← Squared Euclidean distance is (1-1)2+(5-5)2+(4-4)2+(6-6)2 = 0 →
← Squared Euclidean distance is (1-3)2+(5-5)2+(4-4)2+(6-6)2 = 4 →
(Source: http://cybertron.cg.tu-berlin.de/pdci08/imageflight/descriptors.html)
Once we find the feature in the right image that's most similar, we check how far away from the original feature it is, and that tells us how close by or far away the object is.
Definitions (Inputs)
We define these variables to your function:
- image_width
- image_height
- feature_width
- feature_height
- maximum_displacement
We define the variables feature_width and feature_height which result in feature patches of size: (2 × feature_width + 1) × (2 × feature_height + 1). In the previous example, feature_width = feature_height = 2 which gives a 5×5 patch. We also define the variable maximum_displacement which limits the search space. In the previous example maximum_displacement = 3 which results in searching over (2 × maximum_displacement + 1)2 patches in the second image to compare with.
Definitions (Output)
The output will jsut be the absolute minimum squared displacement for each pixel.
Bitmap Images
We will be working with 8-bit grayscale bitmap images. In this file format, each pixel takes on a value between 0 and 255 inclusive, where 0 = black, 255 = white, and values in between to various shades of gray. Together, the pixels form a 2D matrix with image_height rows and image_width columns.
Since each pixel may be one of 256 values, we can represent an image in memory using an array of unsigned char of size image_width * image_height. We store the 2D image in a 1D array such that each row of the image occupies a contiguous part of the array. The pixels are stored from top-to-bottom and left-to-right (see illustration below):
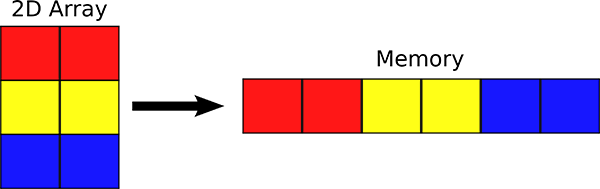
(Source: http://cnx.org/content/m32159/1.4/rowMajor.png)
We can refer to individual pixels of the array by specifying the row and column it's located in. Recall that in a matrix, rows and columns are numbered from the top left. We will follow this numbering scheme as well, so the leftmost red square is at row 0, column 0, and the rightmost blue square is at row 2, column 1. In this project, we will also refer to an element's
column # as its x position, and it's row # as its y position. We can also call the # of columns of the image as its image_width, and the # of rows of the image as its image_height. Thus, the image above has a width of 2, height of 3, and the element at x=1 and y=2 is the rightmost blue square.
Your Project (Due 11/18 @ 23:59:59)
Optimize the naive depth map generator using any of the techniques you learned, including OpenMP. For full credit, the program needs to achieve an average speedup of 4.5x for the odd cases given in the benchmark, and 5.5x for the non-odd cases given in the benchmark. This requirement is worth 100 pts, and this value will be weighed down to the general worth of a project. Your output should remain the same as the output produced by the naive version of the code, and we have provided utilities for you to check the correctness of your code. Please remember, however, that the code provided is not a guarantee of correctness and we expect you to test your code yourself. Code that is incorrect will be given a 0 for grading purposes.
Getting Started
Intialize your repository and get the skeleton code files by entering the following commands:git clone https://mybitbucketusername@bitbucket.org/mybitbucketusername/proj4-xx.git cd proj4-xx git remote add proj4-starter https://github.com/61c-teach/fa16-proj4-starter.git git fetch proj4-starter git merge proj4-starter/master -m "merge proj4 skeleton code"
The only file you need to modify and submit is calcDepthOptimized.c. It is your job to implement an optimized version of calcDepthNaive in calcDepthOptimized.
The rest of the files are part of the framework. It may be helpful to look at and modify some of the other files to more thoroughly test your code. A description of these files is provided below:
Makefile: Defines all the compilation commands.check.c: TestscalcDepthOptimizedon various size randomly generated inputs and compares the results withcalcDepthNaivebenchmark.c: TestscalcDepthOptimizedon increasingly large images and reports the speedup ratio of Naive / Optimised.depthMap.c: Loads bitmap images and calls calcDepthOptimized() to quickly calculate the depth map.utils.c: Defines bitmap loading, printing, and saving functions along with other utilities.test/: Contains the a set of images for testing. You can run your code on these images with depthMap.
You are free to define and implement additional helper functions, but if you want them to be run when we grade your project, you must include them in calcDepthOptimized.c. Changes you make to any other files will be overwritten when we grade your project.
Test your changes by compiling your files with make and running the benchmark or check executable.
make ./check ./benchmark
If you encounter any errors during the compilation process, make clean will help empty your directory, and then simply run make again.
Measuring Performance
For this project, we will measuring performance in terms of the average net speedup between the naive version of the code and the optimised version of the code. The time that the algorithms take is easily calculated by measuring the difference between timestamps before and after the algorithm is ran (in this case we actually use the microprocessor's time stamp counter, which is more accurate than the system clock, but this detail is irrelevant). Once the time it takes for both naive and optimised have been calculated, we simply take the ratio between the two the get the net speedup ratio.
Scoring
Here is the breakdown of how points will be awarded for partial credit. Note that we will not necessarily be using the same sizes provided in the benchmark, however, we will be using similar sizes (nothing far bigger or smaller). Note that despite the fact that we will be benchmarking with similar sizes, this does not exempt you from having working code for smaller images, features, and maximum displacements - for these cases we will not be measuring performance but checking correctness only.
| Speedup Ratio | 0 | 2 | 4 | 4.5 | 5 | 5.25 | 5.5 |
| Point Value | 0 | 20 | 40 | 60 | 80 | 90 | 100 |
Intermediate Cycle Speedups are linearly interpolated based on the point values of the two determined neighbors. Note that heavy emphasis is placed on the middle speedups, with the last couple being worth relatively few points. So don't sweat it if you are having trouble squeezing those last few floating point operations out of the machine!
Here are some suggestions for improving the performance of your code:
- Factor out common calculations and keep the result.
- Avoid recalculating values you have already calculated.
- Avoid expensive operations like divisons or square roots, when unnecessary.
- Unroll loops so that you can use SSE intrinsics and perform 4 operations at a time.
- Don't be afraid to restructure the loops or change the ordering of some operations.
- Padding matrices may give better performance for odd sized matrices.
- Use OpenMP to multithread your code.
- Avoid forking and joining too many times, and avoid critical sections, barriers, and single sections.
- Avoid false sharing and data dependencies between processors.
Debugging and Testing
We have added a debug target to the makefile to assist in debugging. Release/optimized code is difficult for GDB to debug as the compiler is permitted to restructure your source code. While adding in print statements can be helpful, GDB and valgrind can make debugging a lot quicker. To use the debug target, you can run the following commands (followed by running GDB, valgrind, or whatever debugging tools you may find helpful):
make debug
While you are working on the project, we encourage you to keep your code under version control. However, if you are using a hosted repository, please make sure that it is private, or else it could be viewed as a violation of academic integrity.
Before you submit, make sure you test your code on the hive machines. We will be grading your code there. IF YOUR PROGRAM FAILS TO COMPILE, YOU WILL AUTOMATICALLY GET A ZERO. There is no excuse not to test your code.
Submission
The full proj4 is due 11/18 @ 23:59:59. Please make sure only ONE partner submits. To submit proj4, enter in the following:
submit proj4
In addition please push your changes to your bitbucket repository.
Your changes should be limited to calcDepthOptimized.c. If you have any issues submitting please e-mail your TA. Good luck!