Now that you've implemented the Regfile and ALU, you're ready to design your own 2-stage pipelined processor! When you're done, you'll be able to run MIPS code through your assembler and linker, and then on your very own CPU :D
IMPORTANT INFO - PLEASE READ
You are allowed to use any of Logisim's built-in blocks for all parts of this project.
Save often. Logism can be buggy and the last thing you want is to lose some of your hard work. There are students every semester who have had to start over large chunks of their projects due to this.
For this part of the project, you may find it more useful to implement one instruction at a time than one block at a time. Go through the list of instructions and try adding them one by one!
Sample tests for a completed CPU are available! If you do not have them yet, fetch and merge again from the starter repo. You can run the tests in the same way as before: simply run ./run-sanity-test.sh. As always, keep in mind that these tests are NOT comprehensive and you will need to do further testing on your own. To aid you with this, we have provided you with a basic assembler. For usage, see the Testing section, and CPU_TESTING_INSTRUCTIONS.
MAKE SURE TO CHECK YOUR CIRCUITS WITH THE GIVEN HARNESSES TO SEE IF THEY FIT! YOU WILL FAIL ALL OUR TESTS IF THEY DO NOT. (This also means that you should not be moving around given inputs and outputs in the circuits, or adding any new inputs or outputs).
Because the files you are working on are not plain code and circuit schematics, they can't really be merged. DO NOT WORK ON THE SAME FILE IN TWO PLACES AND TRY TO MERGE THEM. YOU WILL NOT BE ABLE TO MERGE THEM AND YOU WILL BE SAD.
0) Obtaining the Files
We added a template for your CPU (cpu.circ), a harness (run.circ), and a data memory module (mem.circ) which you will need for implementing your CPU. We also added a basic assembler (assembler.py) to help you more thoroughly test your CPU. Some sample CPU tests might be coming soon! Please fetch and merge the changes from the proj3-2 branch of the starter repo. For example, if you have set the proj3-starter remote link:
If you do have some other inorrect value for the proj3-starter remote link, delete it first by running:
git remote rm proj3-starter
1) Your Job
You are responsible for constructing the entire datapath and control of the CPU from scratch. Your completed processor should implement the ISA detailed below in the section Instruction Set Architecture (ISA) using a two-cycle pipeline, specified below. Read all of sections 2-5 very carefully!
2) Overview of Files
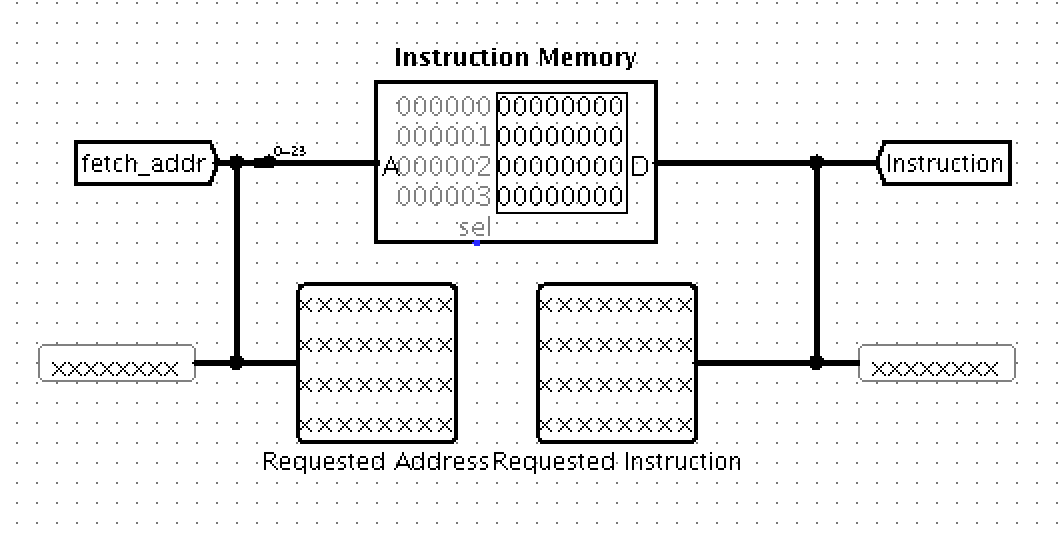
Your processor (cpu.circ) will contain an instance of your ALU and Register File, as well as a memory unit provided in your starter kit and some additional registers you will need. The processor harness run.circ will function as your instruction memory in that it will provide your processor with its program. It feels slightly unconventional in that your CPU will actually be running as a subcircuit of the "instruction memory", so inputs to instruction memory become outputs of our CPU, and outputs of instruction memory become inputs to our CPU. Thus your processor will output the address of an instruction, and accept the instruction at that address as an input. Inspect run.circ to see exactly what's going on. (This same harness will be used to test your final submission, so make sure your CPU fits in the harness before submitting your work!)
Just like in part I, be careful not to move the input or output pins! You should ensure that your processor is correctly loaded by a fresh copy of run.circ before you submit. You can download a fresh copy from the starter repo website.
2.0) Processor
The skeleton for your processor can be found in cpu.circ. Your processor has 2 inputs that come from the harness:
Input Name
Bit Width
Description
INSTRUCTION
32
Driven with the instruction at the instruction memory address identified by the FETCH_ADDRESS (see below).
CLOCK
1
The input for the clock. As with the register file, this can be sent into subcircuits (e.g. the CLK input for your register file) or attached directly to the clock inputs of memory units in Logisim, but should not otherwise be gated (i.e., do not invert it, do not AND it with anything, etc.).
Your processor must provide 8 outputs to the harness:
Output Name
Bit Width
Description
$s0
32
Driven with the contents of $s0. FOR TESTING
$s1
32
Driven with the contents of $s1. FOR TESTING
$s2
32
Driven with the contents of $s2. FOR TESTING
$ra
32
Driven with the contents of $ra. FOR TESTING
$sp
32
Driven with the contents of $sp. FOR TESTING
$hi
32
Driven with the contents of $hi. FOR TESTING
$lo
32
Driven with the contents of $lo. FOR TESTING
FETCH_ADDRESS
32
This output is used to select which instruction is presented to the processor on the INSTRUCTION input.
ONE MORE THING: In addition to these inputs and outputs, you also need to have an LED unit which lights up to signify signed overflow. This indicator should be wired to the signed overflow port of your ALU. This should be viewable in your main circuit.
2.1) Memory
The memory unit is already fully implemented for you! Here's a quick summary of its inputs and outputs:
Output Name
In- or Out-put?
Bit Width
Description
A: ADDR
In
32
Address to read/write to in Memory
D: WRITE DATA
In
32
Value to be written to Memory
En: WRITE ENABLE
In
1
Equal to one on any instructions that write to memory, and zero otherwise
Clock
In
1
Driven by the clock input to cpu.circ
D: READ DATA
Out
32
Driven by the data stored at the specified address.
One important caveat is that the memory is only 64 MB in size, due to the limitations of Logisim's built-in memory block.
If you try to read or write addresses greater than or equal to 226, they will alias to lower addresses.
That is, the address 226 + X will appear to be the same as X.
3) Instruction Set Architecture (ISA)
Your CPU will support the instructions listed below. In all of the instructions you recognize from MIPS, the instruction format, opcode, funct, and register numbers should be taken directly from your greensheet. Notice that not all of the native MIPS functions are listed in the CORE INSRUCTION SET section of the greensheet - you may also need to look in the ARITHMETIC CORE INSTRUCTION SET section, and in the OPCODES, BASE CONVERSION, ASCII SYMBOLS table on the back! There will also be an instruction that is foreign to MIPS: specifications for this new instruction will follow the table, as well as clarifications on some other selected instructions.
Instruction
Format
Shift Left Logical
sll$rd, $rt, shamt
Shift Right Logical
srl$rd, $rt, shamt
Shift Right Arithmetic
sra$rd, $rt, shamt
Jump Register
jr$rs
Jump and Link Register
jalr$rs
Move from Hi
mfhi$rd
Move from Lo
mflo$rd
Multiply
mult$rs, $rt
Divide Unsigned
divu$rs, $rt
Add
add$rd, $rs, $rt
Add Unsigned
addu$rd, $rs, $rt
Sub
sub$rd, $rs, $rt
Sub Unsigned
subu$rd, $rs, $rt
And
and$rd, $rs, $rt
Or
or$rd, $rs, $rt
Exclusive Or
xor$rd, $rs, $rt
Not Or
nor$rd, $rs, $rt
Set Less Than
slt$rd, $rs, $rt
Set Less Than Unsigned
sltu$rd, $rs, $rt
Jump
jlabel
Jump and Link
jallabel
Branch if Equal
beq$rs, $rt, label
Branch if Not Equal
bne$rs, $rt, label
Branch if Equal and Increment NEW!
beqinc$rs, $rt, label
Add Immediate
addi$rt, $rs, immediate
Add Immediate Unsigned
addiu$rt, $rs, immediate
Set Less Than Immediate
slti$rt, $rs, immediate
Set Less Than Immediate Unsigned
sltiu$rt, $rs, immediate
And Immediate
andi$rt, $rs, immediate
Or Immediate
ori$rt, $rs, immediate
Exclusive Or Immediate
xori$rt, $rs, immediate
Load Upper Immediate
lui$rt, immediate
Load Word
lw$rt, offset($rs)
Store Word
sw$rt, offset($rs)
Branch if Equal and Increment (beqinc)
FORMAT: I
OPERATION (RTL): (if R[rs] == R[rt]) PC = PC + 4 + BranchAddr; else R[rt] = R[rt] + 1; BranchAddr = { 14{immediate[15]}, immediate, 2'b0}
OPCODE: 0x6
This operation would be useful for implementing for loops. For instance: for(int i = 0; i < 10, i++)
would probably compile to something like addiu $t0 $0 10 addiu $s0 $0 0 loop: beqinc $t0 $s0 end
Jump and Link (jal)
Our ISA does not expose jump delay slots to hardware, so it does not make sense to store PC + 8 in $ra on a jal instruction! Instead we will store PC + 4
4) Pipelining
Your processor will have a 2-stage pipeline:
Instruction Fetch: An instruction is fetched from the instruction memory.
Execute: The instruction is decoded, executed, and committed (written back). This is a combination of the remaining stages of a normal MIPS pipeline.
You should note that data hazards do NOT pose a problem for this design, since all accesses to all sources of data happens only in a single pipeline stage. However, there are still control hazards to deal with. Our ISA does not expose branch delay slots to software. This means that the instruction immediately after a branch or jump is not executed if the branch is taken. But for the sake of maintaining our CPI (cycles per instruction) we do not always want to stall on a branch -- if we do not take the branch, then we want to continue as we would have. This makes your task a bit more complex. By the time you have figured out if you will take a branch or jump in the execute stage, you have already accessed the instruction memory and pulled out (possibly) the wrong instruction. You will therefore need to "kill" instructions that are being fetched if the instruction under execution is a jump or a taken branch. Instruction kills for this project should be accomplished by MUXing a nop into the instruction stream and sending it into the Execute stage instead of the fetched instruction. Notice that 0x00000000 is a nop instruction; please use this, as it will simplify grading and testing. You should only kill if a branch is taken (do not kill otherwise), but do kill on every type of jump.
Because all of the control and execution is handled in the Execute stage, your processor should be more or less indistinguishable from a single-cycle implementation, barring the one-cycle startup latency and the branch/jump delays. However, we will be enforcing the two-pipeline design. If you are unsure about pipelining, it is perfectly fine (maybe even recommended) to first implement a single-cycle processor. This will allow you to first verify that your instruction decoding, control signals, arithmetic operations, and memory accesses are all working properly. From a single-cycle processor you can then split off the Instruction Fetch stage with a few additions and a few logical tweaks. Some things to consider:
Will the IF and EX stages have the same or different PC values?
Do you need to store the PC between the pipelining stages?
To MUX a nop into the instruction stream, do you place it before or after the instruction register?
What address should be requested next while the EX stage executes a nop? Is this different than normal?
You might also notice a bootstrapping problem here: during the first cycle, the instruction register sitting between the pipeline stages won't contain an instruction loaded from memory. How do we deal with this? It happens that Logisim automatically sets registers to zero on reset; the instruction register will then contain a nop. We will allow you to depend on this behavior of Logisim. Remember to go to Simulate --> Reset Simulation (Ctrl+R) to reset your processor.
5) Approach
First implement a single-cycle CPU, and don't worry about pipelining. To implement your single-cycle CPU, try first making a CPU that does exactly one instruction. Then add all the instructions of that type. Then add another new instruction, etc, until you've implemented a fully-working processor! More in-depth hints can be found in lab7, and we may release more soon as well :) Don't forget to use logisim's built-in blocks -- you shouldn't have to make muxes or comparators by hand!
Once this is working and passing all of your own tests, then try to pipeline your CPU by splitting it into two stages. Think carefully about the way this affects the way stage 1 communicates with the other 4 of MIPS's conventional 5 stages. Then you should test your circuitry on the staff tests, and make more tests of your own!
Logisim Notes
If you are having trouble with Logisim, RESTART IT and RELOAD your circuit! Don't waste your time chasing a bug that is not your fault. However, if restarting doesn't solve the problem, it is more likely that the bug is a flaw in your project. Please post to Piazza about any crazy bugs that you find and we will investigate.
Things to Look Out For
Do NOT gate the clock! This is very bad design practice when making real circuits, so we will discourage you from doing this by heavily penalizing your project if you gate your clock.
BE CAREFUL with copying and pasting from different Logisim windows. Logisim has been known to have trouble with this in the past.
When you import another file (Project --> Load Library --> Logisim Library...), it will appear as a folder in the left-hand viewing pane. The skeleton files should have already imported necessary files.
Changing attributes before placing a component changes the default settings for that component. So if you are about to place many 32-bit pins, this might be desirable. If you only want to change that particular component, place it first before changing the attributes.
When you change the inputs & outputs of a sub-circuit that you have already placed in main, Logisim will automatically add/remove the ports when you return to main and this sometimes shifts the block itself. If there were wires attached, Logisim will do its automatic moving of these as well, which can be extremely dumb in some cases. Before you change the inputs and outputs of a block, it can sometimes be easier to first disconnect all wires from it.
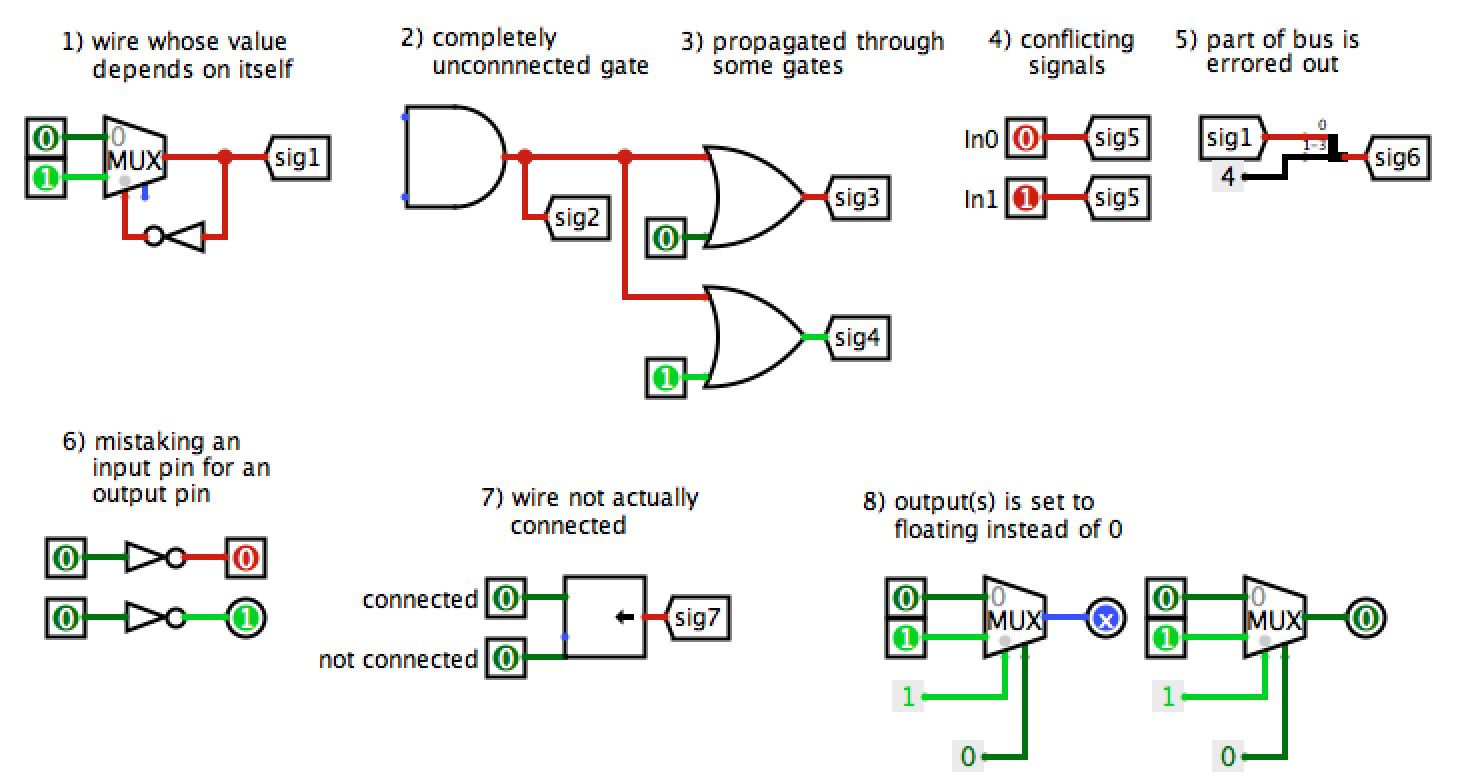
Error signals (red wires) are obviously bad, but they tend to appear in complicated wiring jobs such as the one you will be implementing here. It's good to be aware of the common causes while debugging:
Logisim's Combinational Analysis Feature
Logisim offers some functionality for automating circuit implementation given a truth table, or vice versa. Though not disallowed (enforcing such a requirement is impractical), use of this feature is discouraged. Remember that you will not be allowed to have a laptop running Logisim on the final.
Testing
For part 2, it is somewhat difficult to provide small unit tests such as the ones from part 1 since you are completing the full datapath. As such, the best approach would be to write short MIPS programs and exercise your datapath in different ways. We have provided 3 sample tests for a completed, pipelined CPU, and you can run them in the same way you did in part 1: ./run-sanity-test.sh. To understand what these tests do, look in the tests/assem folder for the MIPS programs that correspond to each test (this might be significantly easier than looking at the expected output). If you are failing a test, investigate as you did in part 1: open the CPU-XXX.circ file corresponding to that test, right click on your CPU and choose "view main", and tick the clock using command-t. Make sure your CPU behaves the way you expect it to.
To help you with testing an incomplete processor, we have also provided reference outputs for two of the tests (addition and multiplication) for a non-pipelined processor. To check your CPU against this standard, you will need to modify tests/sanity_test.py. See CPU_TESTING_INSTRUCTIONS for directions.
Of course, the tests we have provided are not comprehensive, and you will need to do more testing on your own. To facilitate this, we have provided you with a rudimentary MIPS assembler that functions similarly to your project 2. To assemble a MIPS file, simply run the assembler with python and pass in your input file as follows:
vim test.s # create your assembly file. Remember to only use the instructions provided in the ISA above
python assembler.py test.s # This will generate an output file named test.hex
python assembler.py test.s -v # Same as above, but also provides some verbose output on command line.
The assembler supports all the instructions in your project ISA. It supports register names, but not register numbers. You can enter numbers in decimal or in hex, but if you are working with an I-type instruction that 0-extends, negative numbers are not supported. Enter the corresponding hex representation instead.
Note: the assembler has only been tested with python 2.7, so it may be easier to run it remotely off of the hive* servers if you haven't set up your python environments.
Once you have generated the machine code, you'll have to load it into the instruction memory unit in run.circ and begin execution. To do so, first open run.circ and locate the Instruction Memory Unit.
Right click on the memory module and choose "load image." This is where we load the file outputted by the assembler earlier.
Once you've loaded the machine code you can tick the clock manually and watch your CPU execute your program! Using the "mouse" tool, you can right click on the CPU and choose "view main" to see how your datapath is behaving under the given inputs. Or using the "poke" tool, if you click on your CPU, a small magnifying glass will appear. Click on the magnifying glass 2 more times, and you'll reach the same place. You can also fire up MARS at the same time and step through your code there simultaneously. This will allow you to compare the expected behaviour, as seen in MARS, with the behaviour your circuit is exhibiting. Of course, this approach is not valid for the new instructions - for those you'll have to rely solely on your own test assembly code.
Submission
We will submit proj3-2 just like we submitted proj3-1. There are two steps required to submit proj3-2. Failure to perform both steps will result in loss of credit:
First, you must submit using the standard unix submit program on the instructional servers. This assumes that you followed the earlier instructions and did all of your work inside of your git repository. To submit, follow these instructions after logging into your -XXX class account:
cd ~/proj3-XXX # Or where your shared git repo is
submit proj3-2
Once you type submit proj3-2, follow the prompts generated by the submission system. It will tell you when your submission has been successful and you can confirm this by looking at the output of glookup -t.
Additionally, you must submit proj3-2 to your (shared, if you have a partner) Bitbucket repository:
cd ~/proj3-XXX # Or where your shared git repo is
git add -u
git commit -m "project 3-2 submission" # The commit message doesn't have to match exactly.
git tag "proj3-2-sub" # The tag MUST be "proj3-2-sub". Failure to do so will result in loss of credit.
git push origin proj3-2-sub # This tells git to push the commit tagged proj3-2-sub
Resubmitting
If you need to re-submit, you can follow the same set of steps that you would if you were submitting for the first time, but you will need to use the -f flag to tag and push to Bitbucket:
# Do everything as above until you get to tagging
git tag -f "proj3-2-sub"
git push -f origin proj3-2-sub
Note that in general, force pushes should be used with caution. They will overwrite your remote repository with information from your local copy. As long as you have not damaged your local copy in any way, this will be fine.
Deliverables
cpu.circ
alu.circ
regfile.circ
We will be using our own versions of the *-harness.circ and run.circ files, so you do not need to submit those. In addition, you should not depend on any changes you make to those files. I plan to grade your CPU once with your ALU and RegFile and once with the staff solution ALU and RegFile, and then give you the maximum of the two scores, so as to avoid double-jeapardy as well as surprises, as you will be practicing and testing with your own solutions for Part1.
Grading
This project will be graded in large part by an autograder. The autograder cannot tell the difference between a small wiring mistake and a fundametal mistake. You will have the opportunity to submit regrade requests (for a 5% penalty each time I open your file). If you explain what the wiring problem is and I can understand your directions, then I will open your files, fix the wiring problem and run the autograder again. For this reason, please try to make your circuits neat and readable, or you jeapardize your opportunity for regrades!