A. Intro
Download the code for Lab 17 and create a new Eclipse project out of it.
Learning Goals
Today, we tie up loose ends on binary search trees, first considering the algorithm for deleting a node, next analyzing some properties of the inorder successor of a node, and finally modifying the tree slightly to allow finding the kth-largest value quickly.
We also move on to exploring a second way to implement a map. This time, we won't be using hashing, but will instead be using binary search trees. The result will be called a TreeMap rather than HashMap.
B. Delete a Key from a Binary Search Tree
Discussion: Deletion from a BST
Link to the discussionWhen inserting a key, we were allowed to choose where in the tree it should go. The deletion operation doesn't appear to allow us that flexibility; deletion of some keys will be easy (leaves or keys with only one child), but our deletion method has to be able to delete any key from the tree.
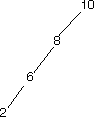
Here are a bunch of binary search trees that might result from deleting the root of the tree
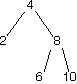
Which ones do you think are reasonable?
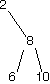
|
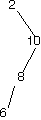
|
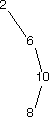
|
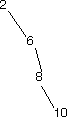
|
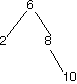
|
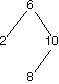
|
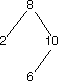
|
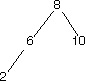
|
|

|
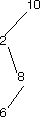
|
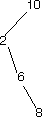
|
A Good Way to Delete a Key
The following algorithm for deletion has the advantage of minimizing restructuring and unbalancing of the tree. The method returns the tree that results from the removal.
- Find the node to be removed. We'll call it
remNode. If it's a leaf, remove it immediately by returningnull. If it has only one child, remove it by returning the other child node. - Otherwise, remove the inorder successor of
remNode, copy itsmyItemintoremNode, and returnremNode.
Q: What is an inorder successor?
A: It is just the node that would appear AFTER the remNode if you were to do an inorder traversal of the tree.
An example is diagrammed below. The node to remove is the node containing 4. It has two children, so it's not an easy node to remove. We locate the node with 4's inorder successor, namely 5. The node containing 5 has no children, so it's easy to delete. We copy the 5 into the node that formerly contained 4, and delete the node that originally contained 5.
| before deletion | after deletion |
|---|---|
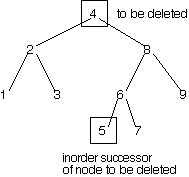 |
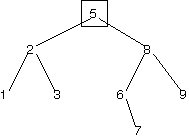 |
Discussion: A General Property of the Inorder Successor
Link to the discussionWhere in a BST is the inorder successor of a node whose right child is null? Note : The node in question is not necessarily the root node.
Inorder Successor
Suppose myNode is the root node in a BST with both a left child and a right child. Will sucNode, the inorder successor of myNode, ALWAYS have a null left child?
|
Yes, always
|
Correct!
|
|
|
No, only sometimes
|
Incorrect.
|
|
|
No, never
|
Incorrect.
|
Animations of BST Algorithms
Here is a cool interactive animation to help you visualize the BST insertion and deletion algorithms. Try inserting a key that ends up as a right child and another key that ends up as a left child. Add some more nodes to the tree, then delete some of them: a node with no children, a node with one child, and a node with two children.
Note that this animation removes from the BST by swapping with the inorder predecessor rather than the inorder successor. Convince yourself this is essentially equivalent.
C. Augmenting a BST
Trading Memory for Speed
Consider the problem of finding the kth largest key in a binary search tree. An obvious way of doing this is to use the inorder enumeration from this week's lab; we could call nextElement until we get the desired key. If k is near the number of keys N in the tree, however, that algorithm's running time is proportional to N. We'd like to do better.
Storing in each node the size of the tree rooted at that node allows the design of an algorithm that runs in time proportional to d, where d is the depth of the tree. Modify the TreeNode class and the BinarySearchTree add method to maintain this information in each TreeNode. Then write and test a method
Comparable kthLargest (int k);that returns the kth largest item in the tree, where k >= 0 and k < the number of keys in the tree.
Discussion: Analyzing Memory/Speed Tradeoffs
Link to the discussionRecall the algorithm to delete a node:
- Find the node to be deleted.
- If it's easy to delete, delete it; otherwise, find its inorder successor, copy the successor's value into the node to be deleted, and delete the successor.
If each node stored a pointer to its inorder successor, would that significantly improve the worst-case performance of the deletion algorithm (expressed as a "runs in time proportional to ..." estimate)? Explain why or why not. Once you get a chance to check your labmates' answers, correct your own if necessary.
D. Introducing the Tree Map
The use of a binary search tree is that it can be used to find items quickly. Imagine that your binary search tree stored key-value pairs rather than just letters or numbers, and when you search the tree, you only search for the key. Now it can be used as a map!
java.util has a class that works exactly like this. It's called, appropriately enough, TreeMap. This is a map that doesn't use hashing.
Self-test: TreeMap Organization
Which of the following trees represents a TreeMap storing the four associations ("Mike", "Clancy"), ("Paul", "Hale"), ("Leonard", "Wei"), and ("Ryan", "Waliany")? (Hint: Remember that TreeMaps maintain the invariants of a BST.)
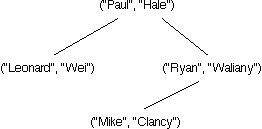
|
Incorrect.
|
|
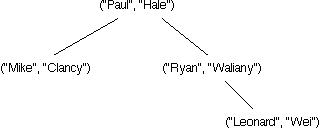
|
Incorrect.
|
|
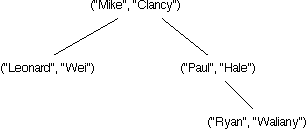
|
Correct!
|
|
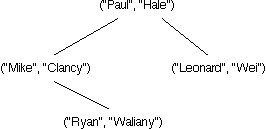
|
Incorrect.
|
A PhoneBook Using a TreeMap
If you haven't yet, switch which partner is coding for this lab.
Remember PhoneBook.java from the lab about hash tables? Modify it to use TreeMap instead of HashMap instead. You may have to modify Person or PhoneNumber as well.
Also run the tests and inspect the results.
Modifying Keys in the TreeMap
We found that when we modified a Key in the PhoneBook TreeMap (Person Object) we were no longer able to look up the PhoneNumber for that Person Object. Or at least, the first test (testCantAccessNumIfChangePersonObj) shows this result. But the second version of this test (testCantAccessNumIfChangePersonObj2) shows the opposite result! In that test, we can modify the Person Object and the PhoneBook is still able to find the PhoneNumber we are looking for. Explain: Why is this happening?
Perhaps take the following steps to find out:
- Test the method in Java to confirm that it finds the entry that it shouldn't.
- Draw a picture of what the
TreeMap(a Binary Search Tree) might look like during each test. Trace the steps that the binary search goes through as it attempts to look up a key. - Ask another pair of students if you get stuck!
- Ask a member of course staff if you and your partner are still stuck.
Callbacks
When we put our Objects in Java TreeMaps and other Java Collections, it needs to call our methods to see if objects are equal, greater than or less than, etc.
Use Eclipse to find out what method is called when we call the methods put and get on a TreeMap. Hint: we think the easiest way to do this is using the Eclipse debugger! If you don't know how to use the debugger, this would be a good excuse to ask for some help!
Modify a PhoneBook to hold Multiple Numbers
Many people have multiple numbers. Modify PhoneBook to map a Person Object to an List of PhoneNumbers.
// This method should now associate a new number with a person
// If this person doesn't have an entry, this will be the only number associated with the person.
public void addEntry(Person personToAdd, PhoneNumber numberToAdd){
// This method should now return an List of PhoneNumbers
public List<PhoneNumber> getNumbers(Person personToLookup){Q: What if we add the same number multiple times with the same Person object?
A: The person will be associated with multiple copies of the same number. (So don't worry about it.)
Discussion: Hash Table vs. BST
Link to the discussionInvent a question about the design of a collection of items whose answer is one of the following:
- a hash table would be a better implementation for the collection
- a (balanced) binary search tree would be a better implementation for the collection
- either a hash table or a (balanced) BST would be good implementations for the collection
You'll need to specify operations to be optimized for your collection.
Here's an example.
- Suppose you want to represent a large set of items so as to optimize the operation of determining if one set is a subset of another. How should you represent the set?
Exercise: Implement your own tree map
Complete MyTreeMap.java to build your own tree map. Don't use java.util.TreeMap, of course! Use a binary search tree you implemented yourself.
If you want to add methods to BinarySearchTree.java for use in MyTreeMap.java, go ahead. You can also make things more public inside BinarySearchTree.java if you wish.
E. Conclusion
Submission
Submit as lab17:
- BinaryTree.java
- BinarySearchTree.java with the new method kthLargest, and potentially other methods
- PhoneBook.java, Person.java, and PhoneNumber.java, now using a TreeMap and supports people having multiple numbers
- MyTreeMap.java
In addition, please fill out this self-reflection form before this lab is due, as a part of your homework assignment. Self-reflection forms are to be completed individually, not in partnership.
Reading
The reading for the next lab is DSA chapters 10.2 - 10.5 (Search Tree Structures).