A. Intro
Download files for lab 16 and make an Eclipse project out of them.
Search in a Collection
An important operation provided by collection classes is finding whether a given item is an element of the collection. You've encountered this operation in several contexts already, for example, the AmoebaFamily activity involving locating an amoeba with a given name.
Search Estimates
For each of the questions below, the answer is one of the five options:
- a constant number
- proportional to
k - proportional to
n - proportional to
log n - proportional to
n^2
Question 1
Suppose that n integers are stored in an IntSequence object. How many comparisons are necessary in the worst case to determine if a given integer k occurs in the sequence?
proportional to n
Question 2
Suppose that n comparable objects are stored in a List object. How many comparisons are necessary in the worst case to determine if a given object k occurs in the list?
proportional to n
Question 3
Suppose that n integers are stored in increasing order in an IntSequence object. How many comparisons are necessary in the worst case to determine if a given integer k occurs in the sequence?
proportional to log n
Question 4
Suppose that n comparable objects are stored in increasing order in a LinkedList object. How many comparisons are necessary in the worst case to determine if a given object k occurs in the list?
proportional to n
Binary Search
We encountered a variation of the binary search algorithm in a guessing game in a lab exercise earlier this semester. Used with an array, it assumes that the elements of the array are in order (say, increasing order). A version that returns the position in the array of the value being looked for works as follows:
- Set
lowto 0 andhighto the length of the array, minus 1. The value we're looking for—we'll call itkey—will be somewhere between positionlowand positionhighif it's in the array. - While
low ≤ high, do the following: (a) Computemid, the middle of the range[low,high], and see if that'skey. If so, returnmid. (b) Otherwise, we can cut the range of possible positions forkeyin half, by settinghightomid-1or by settinglowtomid+1, depending on the result of the comparison. - If the loop terminates with
low > high, we know thatkeyis not in the array, so we return some indication of failure.
The diagrams below portray a search for the key 25. Elements removed from consideration at each iteration are greyed out.
low = 0, high = 14, mid = 7 |
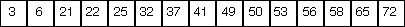 |
low = 0, high = 6, mid = 3 |
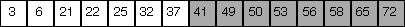 |
low = 4, high = 6, mid = 5 |
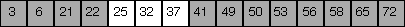 |
low = 4, high = 4, mid = 4 |
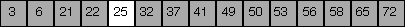 |
Since (roughly) half the elements are removed from consideration at each step, the worst-case running time is proportional of the log base 2 of N, where N is the number of elements in the array.
Self-test: Binary Search with Linked Lists
Consider applying the binary search algorithm to a sorted doubly linked list. The variables low, high, and med would then be references to nodes in the list. Which of the steps in the binary search algorithm would execute significantly more slowly for a collection stored in a sorted doubly linked list than for a collection stored in a sorted array?
- Set
lowto 0 andhighto the length of the array, minus 1. The value we're looking for—we'll call itkey—will be somewhere between positionlowand positionhighif it's in the array. - While
low ≤ high, do the following: (a) Compute the value atmid, the middle of the range[low,high], and see if that'skey. If so, returnmid. (b) Otherwise, we can cut the range of possible positions forkeyin half, by settinghightomid-1or by settinglowtomid+1, depending on the result of the comparison. - If the loop terminates with
low > high, we know thatkeyis not in the array, so we return some indication of failure.
|
Step 2a: It takes extra time (using a linked list) to test to check if we have found the key
|
Incorrect
|
|
|
Step 2a: It takes extra time (using a linked list) to calculate the index of the middle node
|
Incorrect
|
|
|
Step 1: It takes extra time (using a linked list) to figure out the length of the linked list
|
Incorrect
|
|
|
Step 2a: It takes extra time (using a linked list) to access the middle node
|
Correct
|
B. Work with Binary Search Trees
Binary Search Trees
One might naturally look for a linked structure that combines fast search with fast link manipulation of the found node. The tree of choices in a binary search algorithm suggests a way to organize keys in an explicitly linked tree, as indicated in the diagram below.
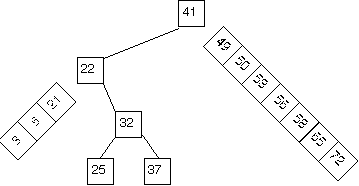
The tree that results is called a binary search tree (BST).
- Let the root value (one of the keys to be stored) be
k. - Put all the keys that are smaller than
kinto a binary search tree, and let that tree bek's left subtree. - Put all the keys that are larger than
kinto a binary search tree, and let that tree bek's right subtree.
(This organization assumes that there are no duplicate keys among those to be stored.)
Given below are an example of a binary search tree and two examples of trees that are not binary search trees.
| BST | nonBST | nonBST |
|---|---|---|
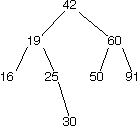 |
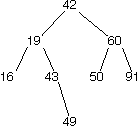 |
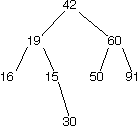 |
Self-test: Identify non-binary search trees
Question 1
What nodes (can be multiple) must be removed from this tree to make it a binary search tree?
43,49. Both of these are in the left subtree but greater than the root node 42, and thus violate the constraint of a BST.
Question 2
What nodes (can be multiple) must be removed from this tree to make it a binary search tree?
15. 15 is less than its parent 19. Removing 15 and relinking the parent of 30 to 19 would create a BST.
The contains method
For this lab, you will need to use the updated version of BinaryTree.java, in the lab16 folder you downloaded. Several changes have been made to this version:
- Unlike the first version of
BinaryTree, this version uses generic types. This means you can have aBinaryTreeof Strings (BinaryTree<String>) or aBinaryTreeof Comparables, and so on. This will prove helpful later in the lab when you need to create theBinarySearchTreesubclass ofBinaryTree. - The variable
myRoot, the nested classTreeNode, and the methodprintare now protected rather than private so that subclasses ofBinaryTreecan make use of them. Also, theTreeNodeclass is no longer static. (Why?) BinaryTreenow implements theIterableinterface and includes a nested class that implements theIteratorinterface. You will modify this nested class later in the lab.
Make sure you look at the new file and understand the changes.
Determining if a given value key is in the tree takes advantage of the invariants of a Binary Search Tree, where each subtree is also a Binary Search Tree. In pseudocode, here is an outline of the helper method
private boolean contains (TreeNode t, T key)Note that the type of key is T, which is the generic type of the BinaryTree class.
- An empty tree cannot contain anything, so if
tisnullreturnfalse. - If
keyis equal tot.myItem, returntrue. - If
key < t.myItem,keymust be in the left subtree if it's in the structure at all so return the result of searching for it in the left subtree. - Otherwise it must be in the right subtree so return the result of search for
keyin the right subtree.
This algorithm can go all the way down to a leaf to determine its answer. Thus in the worst case, the number of comparisons is proportional to d, the depth of the tree.
You will be writing the code for contains later on in the lab. For now, just understand how the implementation of the method works.
Use of Comparable objects
As just noted, finding a value in the tree will require "less than", "greater than", and "equals" comparisons. Since the operators < and > don't work with objects, we have to use method calls for comparisons.
The Java convention for this situation is to have the values stored in the tree be objects that implement the Comparable interface. This interface prescribes just one method, int compareTo (Object). For Comparable objects obj1 and obj2, obj1.compareTo (obj2) is
- negative if
obj1is less thanobj2, - positive if
obj1is greater thanobj2, and - zero if the two objects have equal values.
Once again, we will be using this information later on the in lab.
Balance and imbalance
Unfortunately, use of a binary search tree does not guarantee efficient search. For example, the tree
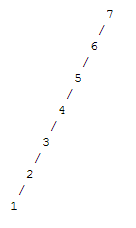
is a binary search tree in which search proceeds the same as in a linked list. We thus are forced to consider the balance of a binary search tree. Informally, a balanced tree has subtrees that are roughly equal in size and depth. Later on in the course, we will encounter specific algorithms for maintaining balance in a binary search tree. Until then, we will work under the possibly unwarranted assumption that we don't need to worry much about balance.
One can prove, incidentally, that search in a BST of N keys will require only about 2 ln N comparisons (ln is the "natural log" of N) if the keys are inserted in random order. Well-balanced trees are common, and degenerate trees are rare.
Count of maximally imbalanced trees
There are 14 different binary search trees with 4 nodes. How many of the 14 are as deep as possible (i.e. they cause the search algorithm to make 4 comparisons in the worst case)?
(Luckily these bad trees get rarer when N gets larger.)
8 binary search trees. Starting at the root node, we are constrained to select a single child for this root node, and it can be either to the left or to the right of this root node. Similarly for this child node. So we have 2^3 possibilities.
Insertion into a BST
As you may have noticed in the preceding step, there are a large number of binary search trees that contain a given N keys. Correspondingly, there are typically a bunch of places in a BST that a key to be inserted might go, anywhere from the root down to a leaf. Given below are two trees; the tree on the right shows one possible way to insert the key 41 into the tree on the left.
|
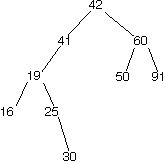 |
To minimize restructuring of the tree and the creation of internal nodes with only one child, we choose to insert a new key only as a new leaf. The following pair of methods does this.
public void add(T key) {
myRoot = add(myRoot, key);
}
private TreeNode add(TreeNode t, T key) {
if (t == null) {
return new TreeNode(key);
} else if (key.compareTo(t.myItem) < 0) {
t.myLeft = add(t.myLeft, key);
return t;
} else {
t.myRight = add(t.myRight, key);
return t;
}
}A common pattern for methods that modify trees is the following:
Make a recursive call to modify a subtree— this call returns the root of the modified subtree.
Store the reference to the modified subtree into the appropriate TreeNode field (myLeft or myRight),
and return the root of the current tree. (You may have encountered this in methods involving ListNodes.) In the code above, this is done in the statements
t.myLeft = add(t.myLeft, key);
return t;and
t.myRight = add(t.myRight, key);
return t; A BinarySearchTree class, extending Binary Tree
Now it's time to start writing code!
Since binary search trees share many of the characteristics of regular binary trees, we can define the BinarySearchTree class using inheritance. Do this as follows.
1) Create a file BinarySearchTree.java with the class definition
public class BinarySearchTree<T extends Comparable<T>> extends BinaryTree<T> ...This class definition is a slightly more complicated use of generic types than you have seen before in lab. Previously, you saw things like BinaryTree<T>, which meant that the BinaryTree class had a generic type T that could be any class, interface, or abstract class that extends Object. In this case, BinarySearchTree<T extends Comparable<T>> means that the BinarySearchTree class has a generic type T that can be any class, interface, or abstract class that implements the Comparable<T> interface. In this case, Comparable<T> is used because the Comparable interface itself uses generic types (much like the Iterable and Iterator interfaces).
(The BinarySearchTree class shouldn't have any instance variables. Why not?)
2) Finally, supply a contains method for the BinarySearchTree class.
public boolean contains(T key)takes a Comparable object as argument and checks whether the tree contains it. (Recall that Comparable objects provide an int compareTo method that returns a negative integer if this object is less than the argument, a positive integer if this is greater than the argument, and 0 if the two objects have equal values.) Remember to use the helper method from earlier in the lab.
Also, supply an add method:
public void add(T key)takes a Comparable object as argument and adds it to the tree only if it isn't already there.
The trees you create with the add method will thus not contain any duplicate elements.
Note: the code for add is above. Add it to BinarySearchTree and implement contains in a similar fashion.
3) Test your code. In particular, using only calls to add inside JUnit or a main method, create the tree shown below.
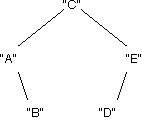
Comparison Counting
Question
How many comparisons between keys were necessary to produce the sample tree in the previous step (shown below)? Ignore equality checks.
6 comparisons.
C. Additional Exercise
One More Exercise
If you haven't yet switched which partner is coding for this lab, do so now.
For the end of this lab, complete one more exercise. This will be in the BinaryTree class rather than the BinarySearchTree class. As a warning, past 61BL students have found this exercise quite difficult.
Write and test a constructor for the BinaryTree class that, given two ArrayLists, constructs the corresponding binary tree (NOT necessarily a BST). The first ArrayList contains the objects in the order they would be enumerated in a preorder traversal; the second ArrayList contains the objects in the order they would be enumerated in an inorder traversal. For example, given
ArrayLists ["A", "B", "C", "D", "E", "F"] (preorder) and ["B", "A", "E", "D", "F", "C"] (inorder), you should initialize the tree as follows:
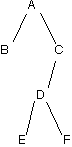
You may assume every item in the tree is unique when doing this exercise.
D. Conclusion
Summary
Next lab, we'll finish up trees and show how they can be applied to create maps.
Submission
Please submit the files 'BinarySearchTree.java' and 'BinaryTree.java'.