In the remainder of that lab we're going to be going over a couple of cool applications of graphs in the real world that might be familar to you. The following discussions are all conceptual overviews. You are not expected to understand the topics on a technical level.
Vertices and edge of the World-Wide Web
The world-wide web can be viewed as adirecteed graph in which the vertices are static pages, and two vertices are connected by an edge if one page contains a hyperlinke to the other. A very small slice of the Internet appears below.
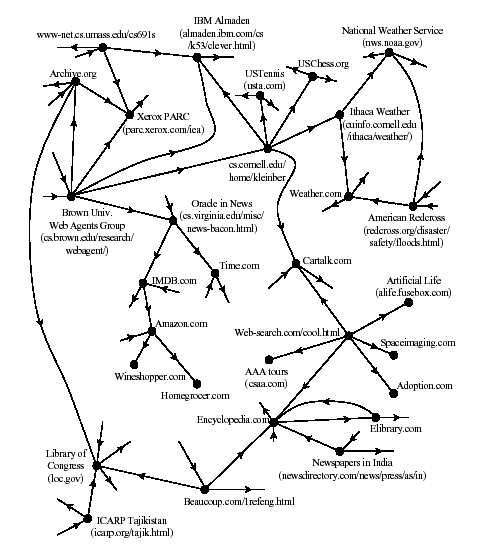
This is a very large graph. In 2001, there were estimated to be over four billion web pages. As of 2014, estimates on the size of the web vary wildly, and some have reached as high as at least one trillion.
The shape of the web
Most agree that a very large portion of the Internet is a strongly connected core of web pages, all of which are reachable from one another by following links. The majority of web sites you visit probably have pages in this core. However, it is also known that a significant portion of the internet is made up of pages that are not a part of this strongly connected core, though the number and nature of these pages remains a topic of debate.
Web crawlers and search engines
A web crawler is a program that traverses the graph that is the Internet, looking for "interesting" pages to index. A search engine takes a query and presents pages from the index, with the most "interesting" ones first.
The index is a massive table; the keys are the content words, and the values are the associated URLs. The crawler adds pages to the table, and the search engine retrieves them. The crawler must also maintain a second table to know what pages it has visited already.
This is a simplified explanation of how search engines work, but hopefully you can see how the data structures we've studied in this class apply.
How web crawlers define "interesting"
A Web crawler isn't able to search the whole Web; it's just too big. A user often finds that listings are three or four months out of date. The best indexes cover only around 25% of the accessible pages. Thus there is an incentive to maximize the "bang for the buck" by visiting only those pages that are likely to yield interesting elements of the index.
The search engine faces a similar problem when answering a query. There may be an enormous number of indexed pages that are possibly relevant to the query, and the search engine has to order them so that the most interesting pages get presented to the user first.
"Interesting" was traditionally defined by content. For example, a page might be evaluated according to how many "interesting" words it contained. On the search engine side, a page might be evaluated according to the position of the query words in the page (nearer the beginning is better), on the number of times previous users have accessed that page, or on the "freshness" or recency of the page.
Soon, however, users seeking to maximize exposure to their pages uncovered ways to trick the content evaluation. For example, they would include many invisible copies of a popular keyword in their pages.
The big innovation of Google's inventors Larry Page and Sergey Brin (former Stanford grad students) was to include properties of the graph structure in the test for interestingness.
Initially they gave priority to pages with higher in-degree, on the assumption that the more people that link to your page, the better your page must be. They later refined that idea: the more interesting pages link to you, the more interesting you must be. Web crawlers can use the same criterion to tell whether to continue their search through a given page.
Discussion: Think about a way to fool "interestingness" criteria
One reason for not just tallying in-degrees of pages was that devious users found a way to fool the system. Describe a way to design a Web site to make the pages look more "interesting," where "interesting" means "having a higher in-degree."
Improving crawler/search engine performance
Improving the performance of web crawlers and search engines is a thriving area of research. It relates to a wide variety of computer science research:
- natural language understanding
- parallel computing algorithms
- user interface design and evaluation
- graph theory
- software engineering