This lab makes extensive use of starter files that we provide here, so make sure to download them! After downloading the zip archive, don't forget to extract the files.
In this lab, we'll be working with MapReduce, a programming paradigm developed by Google, which allows a programmer to process large amounts of data in parallel on many computers.
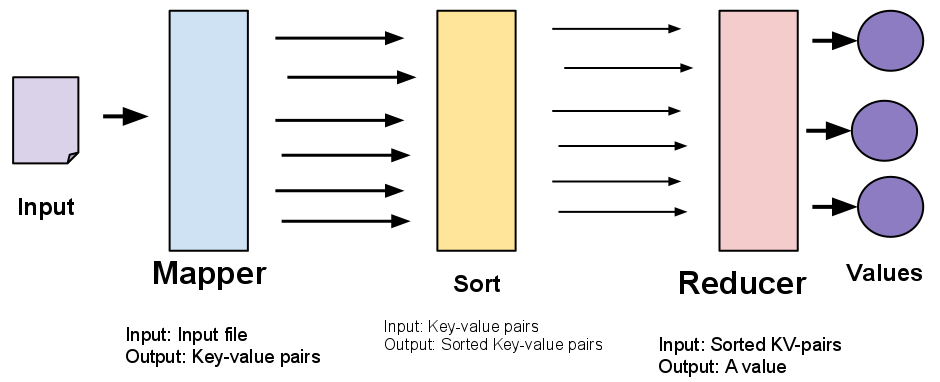
A computation in MapReduce consists two components: the mapper and the reducer.
The mapper takes an input file, and prints out a series of key-value pairs:
age 29
name cecilia
job gradstudent
salary 42
In the example above, the key-value pairs are:
The reducer takes the (sorted) output from the mapper, and outputs a single value for each key. The mapper's output will be sorted according to the key.
The following diagram summarizes the entire MapReduce pipeline:
This lab is split up into two parts: 1. Serial MapReduce: to introduce our MapReduce framework, we will first use a non-parallelized version. Even with this limitation, we can still do quite a lot of data processing! 2. Parallelized MapReduce: the real power of MapReduce comes from parallelization. The same MapReduce jobs from Part 1 can be executed much faster by using multiple computers (i.e. a cluster) at the same time. For this lab, we will be using Hadoop, an open source implementation of the MapReduce paradignm.
In this section, we introduce the framework for mappers and reducers. We will be running MapReduce jobs locally, so no parallelization occurs during this section. However, observe that we can still do an impressive amount of data processing just by defining two simple modules: the mapper and the reducer!
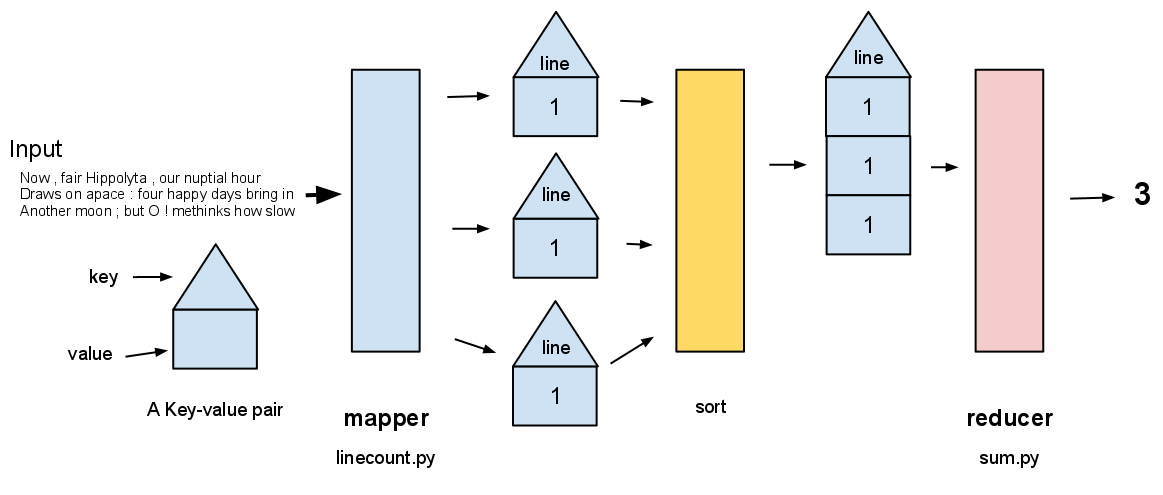
Our first exercise will be counting the number of lines in one of Shakespeare's plays.
To formulate this as a MapReduce problem, we need to define an
appropriate mapper and reducer function.
Recall what the mapper does: for each line in a text file, the mapper outputs a key-value pair. What should our key-value pairs be for our line counting example?
For example, the mapper will take in an input file like this:
so much depends
upon
a red wheel
barrow
glazed with rain
water
beside the white
chickens.
(notice there are 8 lines); it then outputs a sequence of key-value pairs like this:
'line' 1
'line' 1
'line' 1
'line' 1
'line' 1
'line' 1
'line' 1
'line' 1
The reducer takes this sequence and simply adds up all the values that are associated with the key 'line':
'line' 8
This is illustrated by the following diagram:
Let's examine the code mapper and reducer.
line_count.pyIn your current directory should be a file line_count.py with the
following body:
#!/usr/bin/env python3
import sys
from ucb import main
from mr import emit
@main
def run():
for line in sys.stdin:
emit('line', 1)
line_count.py is the mapper, which takes input from stdin (i.e.
'standard in') and outputs one key-value pair for each line to
stdout (i.e. 'standard out', which is typically the terminal
output).
Let's run line_count.py by feeding it the_tempest.txt
(provided with the starter files). The question is, how do we give
the_tempest.txt to line_count.py via stdin? We'll use the Unix
pipe '|' feature (Note: the 'pipe' key '|' isn't lowercase 'L',
it's (typically) Shift+Backslash):
Note: You will probably have to tell Unix to treat line_count.py
as an executable by issuing the following command:
chmod +x line_count.py
Once you've made line_count.py executable, type in the following
command:
cat the_tempest.txt | ./line_count.py
Recall that the cat program will display the contents of a given file
to stdout.
If you've completed line_count.py correctly, your terminal output
should be full of key-value pairs, looking something like:
'line' 1
'line' 1
'line' 1
...
'line' 1
Unix pipe-ing takes the output of one program (in this
case, the cat program), and 'pipes' it as the input to another
program (typically via stdin). This technique of piping programs
together is called "mudlar programming" and is ubiquitous in Unix-style
programming. Modular programming allows us to write small, simple
programs and chain them together to accomplish complicated tasks.
In your current directory should be the file sum.py. The body of this
file should be:
#!/usr/bin/env python3
import sys
from ucb import main
from mr import values_by_key, emit
@main
def run():
for key, value_iterator in values_by_key(sys.stdin):
emit(key, sum(value_iterator))
Let's break down the process:
values_by_key is a function that reads input from stdin, and
groups all key-value pairs that have the same key. For example,
'line' 1
'line' 1
'line' 1
will turn into the following pair:
('line', [1, 1, 1])
Note: the second element should actually be an iterator, not a Python list; it is represented with square brackets for visual clarity.
The variables key and value_iterator get bound to their
respective values in the example above:
key: 'line'
value_iterator: [1, 1, 1]
For each of these key-iterator pairs, sum.py will add up all the
values in the iterator and output this new value with the same key:
'line' 3
The emit function prints out a key and a value in the format
shown above. emit also handles logistics for parallelization,
which becomes important in Part 2 of the lab.
You can think of the reducer as taking all the values of a key and collapsing it into a single value.
Now that we have the mapper and the reducer defined, let's put it all together in the (simplified) MapReduce framework:

Note: You will probably have to tell Unix to treat sum.py as an
executable by issuing the following command:
chmod +x sum.py
Once you've done this, issue the following Unix command:
cat the_tempest.txt | ./line_count.py | sort | ./sum.py
Notice that we're using the Unix program sort, which is a built-in
Unix program. As you'd expect, sort will, given a file, sort the
lines of the file - by default, it will sort it alphabetically.
Take a moment and make sure you understand how the above Unix command is exactly the MapReduce framework (Map -> Sort -> Reduce). What's neat is that, in a very simple manner, we executed the MapReduce idea of using mappers and reducers to solve a problem. However, the main benefit of using the MapReduce idea is to take advantage of distributed computing - don't worry, we'll do that soon!
Question 1: Use the MapReduce framework (i.e. Map -> Sort -> Reduce) to count the number of times the following common words occur:
A question to ponder is: will you need to create a new mapper, a new reducer, or both?
Now that we are familiar with the MapReduce framework, it's time to parallelize the process! Parallelization across multiple computers allows programmers to process vast amounts of data (think Google or Facebook) in a reasonable amount of time.
In this part of the lab, we will be using the Hadoop implementation
of MapReduce. The provided file mr.py will take care of the details
of communicating with Hadoop through Python. All you have to worry
about is writing the mapper and reducer, just like before!
In order to use Hadoop, you need to connect to a special Berkeley
server called icluster1. This server is able to make connections to
a cluster of computers for distributed computing. You can connect just
like you normally would to a Berkeley server:
ssh -X icluster1.eecs.berkeley.edu
You will be asked if you want to remember the RSA signature -- type yes. You will then be asked to login to your class account.
Note: you will only be able to do this part of the lab if you ssh
onto the icluster1 server.
Finally, some Unix environment variables need to be set. Go to the
directory containing the lab starter files. One of them should be a
file called envvars. Simply run the following command:
source envvars
Now you're ready to start using Hadoop!
For various reasons, the Hadoop framework uses its own filesystem
separate from the filesystems on your class account. To interact with
the Hadoop filesystem, we'll be using mr.py:
cat
python3 mr.py cat OUTPUT_DIR
This command prints out the contents of all files in one of the
directories on the Hadoop FileSystem owned by you (given by
OUTPUT_DIR).
ls
python3 mr.py ls
This command lists the contents of all output directories on the Hadoop FileSystem.
rm
python3 mr.py rm OUTPUT_DIR
This command will remove an output directory (and all files within it) on the Hadoop FileSystem. Use this with caution - remember, there's no 'undo'!
run
python3 mr.py run MAPPER REDUCER INPUT_DIR OUTPUT_DIR
This command will run a MapReduce job of your choosing, where:
MAPPER: a Python file that contains the mapper function, e.g.
line_count.pyREDUCER: a Python file that contains the reducer function, e.g.
sum.pyINPUT_DIR: the input file, e.g. ../shakespeare.txtOUTPUT_DIR: the name of the directory where you would like the
results of the MapReduce job to be dumped into; e.g. myjob1We are going to perform the same line counting example as we did in
Part 1, but with Hadoop. Make sure that your line_count.py, sum.py,
and mr.py are in the current directory, then issue the command:
python3 mr.py run line_count.py sum.py ../shakespeare.txt mylinecount
Your terminal should then be flooded with the busy output of Hadoop doing its thing. In particular, the output should contain lines that look like this:
map 0% reduce 0%
map 100% reduce 0%
map 100% reduce 17%
map 100% reduce 67%
map 100% reduce 100%
Job complete: job_201311261343_0001
Output: output/mylinecount
This tells you the progress of your MapReduce job, specifically how many mappers and reducers have completed.
Once it's finished, you'll want to examine the Hadoop results! To do this, first issue the following command to see the contents of your Hadoop directory:
python3 mr.py ls
You should see a directory listing for your mylinecount job. To view
the results of this job, we'll use mr.py's cat command:
python3 mr.py cat mylinecount/part-00000
As an interesting reference point, one TA ran this MapReduce job on a
lightly-loaded icluster1, but totally in serial, meaning that each
map job had to be done sequentially. The total line_count job took on
the order of 5-8 minutes. How much faster was it to run it with Hadoop
using distributed computing, where the work can be done in parallel?
Question 2: Take your solution from Question 1 and run it
through the distributed MapReduce (i.e. by using mr.py) to discover
the number of occurrences of the following words in the entirety of
Shakespeare's works:
Question 3: One common MapReduce application is a distributed word count. Given a large body of text, such as the works of Shakespeare, we want to find out which words are the most common.
Write a MapReduce program that returns each word in a body of text
paired with the number of times it is used. For example, calling your
solution with ../shakespeare.txt should output something like:
the 300
was 249
thee 132
...
Note: These aren't the actual numbers.
You probably will need to write a mapper function. Will you have to write a new reducer function, or can you re-use a previously-used reducer?
Question 4a: We've included a portion of the trends project in the file that you copied at the beginning of the lab in the files "trends.py" and "data.py". We're going to calculate the total sentiment of each of Shakespeare's plays much the same way that we calculated the total sentiment of a tweet in the trends project.
In order to do this, we need to create a new mapper. The skeleton for
this new mapper is in the file sentiment_mapper.py. Fill in the
function definition so that it emits the average sentiment of each line
fed to it.
Note that we need to provide our code with the big sentiments.csv file.
We've already stored this for you on the distributed file system that
Hadoop uses. To make sure the file is available to our code, we use the
run_with_cache command instead of the "run" command which allows us
to provide one additional parameter: the path (on the virtual file
system) to the cache file which contains the sentiments. Don't worry
too much about this part -- it's just the specifics of our
implementation.
Long story short, we will use the following command to run this map reduce task:
python3 mr.py run_with_cache sentiment_mapper.py sum.py ../shakespeare.txt MY_OUTFILE ../sentiments.csv#sentiments.csv
Question 4b: Now, we will determine the most commonly used word.
Write a Python script file most_common_word.py that, given the output
of the program you wrote in part 3 (via stdin), returns the most
commonly used word. The usage should look like (assuming you named the
Hadoop job output q3):
# python3 mr.py cat q3 | python3 most_common_word.py
Question 4c: Now, write a Python script file that, given the
MapReduce output from Q3 (via stdin), outputs all words used
only once, in alphabetical order. Finally, output the results into a
text file singles.txt. The Unix command should look like this:
# python3 mr.py cat q3 | python3 get_singles.py | sort > singles.txt
Question 5: In this question, you will write a MapReduce program that, given a phrase, outputs which play the phrase came from.
Then, use your solution to figure out which play each of the following famous Shakespeare phrases came from:
Hint: In your mapper, you'll want to use the get_file() helper
function, which is defined in the mr.py file. get_file() returns
the name of the file that the mapper is currently processing - for
../shakespeare, the filenames will be play names. To import
get_file, include the following line at the top of your Python
script:
from mr import get_file
Also, you might want to look at the included set.py reducer which
reduces the values of each key into a set (i.e. removing duplicates).
To run the MapReduce job, use the following command:
python3 mr.py MAPPER REDUCER ../shakespeare MY_OUTFILE
where MAPPER is the name of your mapper file and REDUCER is the
name of your reducer file.